Under the hood
Taking a deeper dive 🤿 into the design of Filgas to better understand how it works and reveal the inner workings of this application, we will try to outline a vibrant set of technologies used as well as how it all comes together to provide a unique set of features and contribute to the filecoin ecosystem.
Client Side Application 💻
The client side application or the frontend for filgas focuses on how we display all the information and insight gathered by indexing filecoin transactions and block data. Built using NextJS/React, it is an extremely responsive and performant web application that showcases interative graphical illustrations and accessible tools to analyze blockchain data. The frontend relies on the GraphQL server to consume information from the backend.
Server Side Application ⚙️
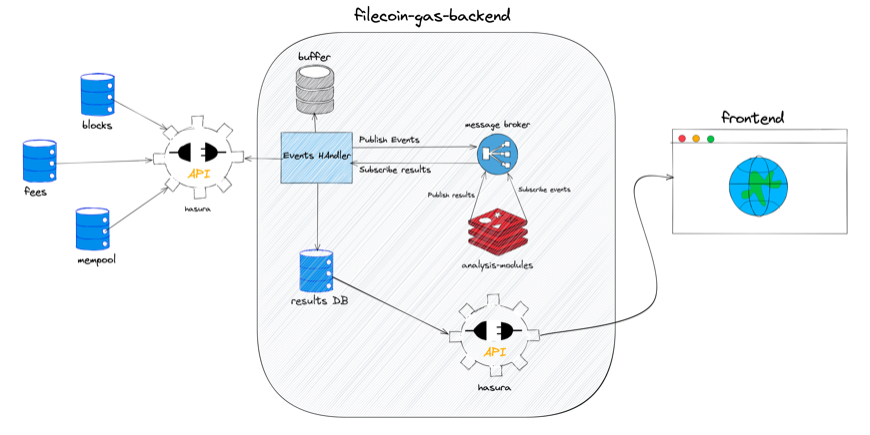
The heart and soul of the project that powers the frontend and responsible for ingesting, analyzing, storing and exposing meaningful data for the frontend application.
This can be further broken down into three major parts with their own set of responsibilities.
-
Lotus nodes for filecoins
Filecoion nodes that are part of the whole network. These expose APIs which are used to consume raw data from the node and the indexers destruct + store this data to power Filgas.
-
Zondax's Data Indexers
The data indexer's sole purpose is to make sense of raw data ingested from the lotus node and store meaninful data in the database which can then be used to power applications such as Filgas.
There exist different types of indexers specific to the kind of data that need to be processed, namely:
- Historical data indexer
- Fees indexer
- Mempool indexer
-
Processed data
Data output from the indexers is here referred to as processed data, this powers two important features:
- Gas probabilistic model processor
- GraphQL API to serve frontend
- Uses hasura to expose the processed data. Hasura come with a GraphQL server that exposes the data through REST endpoints.
Filgas Design Schematic: